【python案例】按序统计文本中单词出现的个数
加入一个文本中有数几段话,几千个英文单词,现在我们要来统计其中的因为跟单词出现的个数。
用python很容易实现。
第一步
打开文件,读取所有内容。
这里我们用
#打开文件 f = open(filename, 'rb') # 读取全部内容 s = f.read()
第二步
获取内容中全部英文单词,用python的re正则来获取,这里列举出了三种方式。
#第一种方式获取所有英文单词
reObj = re.compile('\b?(\w+)\b?')
words = reObj.findall(s)
#第二种方式获取所有英文单词
#reObj = re.compile('[a-zA-Z0-9]+')
words = reObj.findall(s)
#第三种方式获取所有英文单词
#words = re.split('\W+', s)
其中第一种二种可以将compile预编译中的正则合并到findall中。
第三步
通过字典的方法将字段写入到字典中,并且判断重复的填写数量。
第四步
用sorted方法将字典转换为列表后然后排序
第五步
循环输出。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import string
import re
# 统计英文字符出现的字数
def word_count(filename):
#打开文件
f = open(filename, 'rb')
# 读取全部内容
s = f.read()
#第一种方式获取所有英文单词
reObj = re.compile('\b?(\w+)\b?')
#第二种方式获取所有英文单词
#reObj = re.compile('[a-zA-Z0-9]+')
words = reObj.findall(s)
#第三种方式获取所有英文单词
#words = re.split('\W+', s)
#新建字典
wordDict = dict()
for word in words:
# 如果字典中存在则数量加1,不存在等于1
if word.lower() in wordDict:
# 转化为小写
wordDict[word.lower()] += 1
else:
wordDict[word.lower()] = 1
f.close()
#将字典转换为列表以后,然后排序,按照值,返回的是一个列表
wordDict = sorted(wordDict.items(), key = lambda x: x[1], reverse = True)
#输出单词和数量
for key, value in wordDict:
print('%s: %s' % (key, value))
if __name__ == '__main__':
filename = 'words.txt'
word_count(filename)
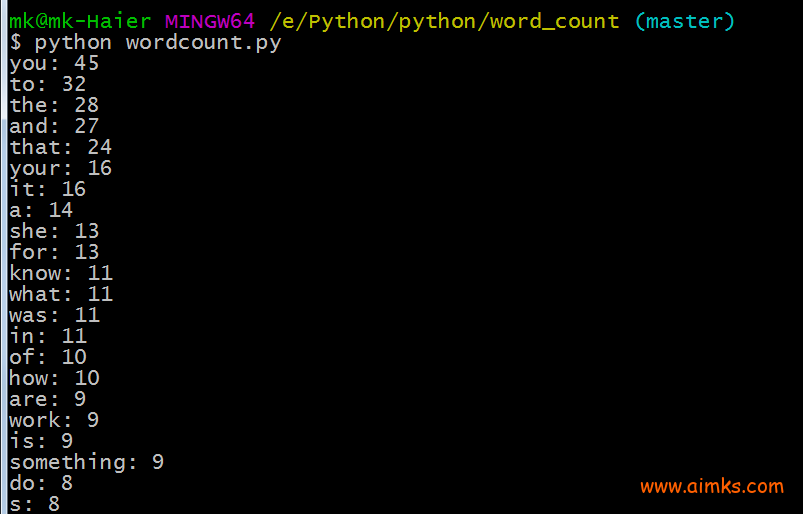
最后我们来看看结果。
【python案例】批量修改目录内的图片尺寸 layer.prompt使文本框为空的情况下也能点击确定


文章不错支持一下吧