PYTHON
scrapy爬虫数据保存为txt,json,mysql的方法

上次我们写了一个将明凯博客首页的数据保存到数据库的方法。 但是有一些朋友说不需要将数据保存到mysql中,他们只需要保存到txt,或者csv,或者json格式中。 Python蜘蛛scrapy的采集数据到数据库的详细方法 那么这篇文章就是来教我们来怎么写,保存到txt,json, […]
python中出现IndentationError: unexpected indent的解决办法
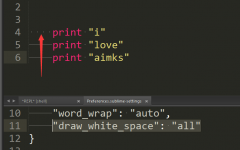
今天我将我的代码复制到另外一个程序上面,代码很简单,每行看起来该缩进的都缩进了,运行的时候出现了如下错误: 报错 IndentationError: unexpected indent 我们看看下面的代码 #-*- coding:utf-8 -*- print “i” print […]
scrapy中xpath使用extract()的时候[0]位置分析

xpath解析使用extract()的时候,一共有5种情况,刚开始做xpath的时候可能不懂,我在这里就全部解析一下。 item[‘link’]=sel.xpath(‘./h2/a/@href’) item[‘link’]=sel.xpath(‘./h2/a/@href’).ex […]
python中文字符编码ot in range(128)问题的解决办法

我们都知道python中中文支持支持需要在顶部编写# -*- coding: utf-8 -*-, 这样,注释有中文也不会报错。 但是加了这个只是代表程序运行不出错,但是你加入print 中文的时候还是会报错编码问题。 下面我们来一一讲解一下。 print 1 + 2 print […]
Sublime Text3安装SublimeREPL方便运行Python的的方法

SublimeREPL是编辑器Sublime Text上的一个支持各种语言解释器的插件,可以方便我们在编辑器上编写完代码进行调试。 安装SublimeREPL 1、调用ctrl+shift+p,输入:sublimerepl选择并安装;(本机安装时候居然找不到这个sublimere […]
Python蜘蛛scrapy的采集数据到数据库的详细方法

编写爬虫其实很简单,现在我们以最短的时间写一个最简单的爬虫,来爬写明凯博客首页的内容。 爬虫编写的基本流程: 创建一个新的Scrapy工程 定义你所需要要抽取的Item对象 编写一个spider来爬取某个网站并提取出所有的Item对象 编写一个Item Pipline来存储提取出 […]
windows Git Bash 无法运行python解决方法

以前运行cmd命令都是在cmd里面的,但是那个页面实在是太丑了,后面我就全部用git bash来运行window下的命令了。 但是在git bash 中运行下python – -version 或 pip list 命令,都是可以正常使用。 但是输入python 确没 […]
win7安装python和scrapy的安装方法

最近发现一个同事是python大神,虽然我对python没什么兴趣,但是我对蜘蛛有很大的兴趣。 以前我对火车头,八爪鱼这些东西很熟悉,可是要做一些定制化的采集,这些东西还是有一点苍白,无法做到三级四级甚至五级页面的采集。 于是,他教我学python,就着文档,半天居然就写出了自己 […]