后台开发
PHP中var_dump展示不全出现省略号的解决办法

我们使用php的var_dump函数,可以更直观的查看输出结果,包括类型,数量等详细信息。 此函数显示关于一个或多个表达式的结构信息,包括表达式的类型与值。 数组将递归展开值,通过缩进显示其结构。 但是在使用过程中,发现数组深度高,数组数量大等情况会出现省略号,这是什么原因呢。 […]
php数组中删除元素之重新索引的三种方法

如果要在某个数组中删除一个元素,可以直接用的unset。 < ?php $arr = array('a','b','c','d'); unset($arr[1]); echo $array[1]; // error Undefined offset print_r($arr); […]
PHP生成唯一订单号的四种方法

我们做商城类项目经常需要生成唯一订单号, 我们来用总结出PHP生成四种方法。 方法一: return date(‘Ymd’) . str_pad(mt_rand(1, 99999), 5, ‘0’, STR_PAD_LEFT); 方法二: return date(‘Ymd’).s […]
清除scrapy爬虫满屏的打印信息的问题

Scrapy 提供了 log 功能。可以通过 scrapy.log 模块使用。 在运行scrapy crawl aimks时,屏幕上满屏的打印信息,实在是不好找错误信息。 我查了下scrapy的log服务,他默认开启的是debug模式。 log 服务必须通过显式调用 scrapy […]
scrapy在不同的Request之间传递数据的办法

有一次,我在采集淘宝数据的时候,发现我需要在列表页抓一些数据,也需要在详情页抓一些数据,有时候我也需要在详情的js代码源码中再抓取一些数据。 这就涉及到不同的request之间传递数据的方法了。 一个用户完整的信息要在多个Request中获取,需要在请求之间传递参数。 直到该用户 […]
scrapy爬虫数据保存为txt,json,mysql的方法

上次我们写了一个将明凯博客首页的数据保存到数据库的方法。 但是有一些朋友说不需要将数据保存到mysql中,他们只需要保存到txt,或者csv,或者json格式中。 Python蜘蛛scrapy的采集数据到数据库的详细方法 那么这篇文章就是来教我们来怎么写,保存到txt,json, […]
python中出现IndentationError: unexpected indent的解决办法
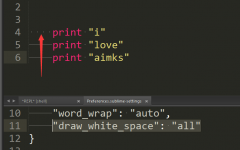
今天我将我的代码复制到另外一个程序上面,代码很简单,每行看起来该缩进的都缩进了,运行的时候出现了如下错误: 报错 IndentationError: unexpected indent 我们看看下面的代码 #-*- coding:utf-8 -*- print “i” print […]
scrapy中xpath使用extract()的时候[0]位置分析

xpath解析使用extract()的时候,一共有5种情况,刚开始做xpath的时候可能不懂,我在这里就全部解析一下。 item[‘link’]=sel.xpath(‘./h2/a/@href’) item[‘link’]=sel.xpath(‘./h2/a/@href’).ex […]
python中文字符编码ot in range(128)问题的解决办法

我们都知道python中中文支持支持需要在顶部编写# -*- coding: utf-8 -*-, 这样,注释有中文也不会报错。 但是加了这个只是代表程序运行不出错,但是你加入print 中文的时候还是会报错编码问题。 下面我们来一一讲解一下。 print 1 + 2 print […]
Sublime Text3安装SublimeREPL方便运行Python的的方法

SublimeREPL是编辑器Sublime Text上的一个支持各种语言解释器的插件,可以方便我们在编辑器上编写完代码进行调试。 安装SublimeREPL 1、调用ctrl+shift+p,输入:sublimerepl选择并安装;(本机安装时候居然找不到这个sublimere […]